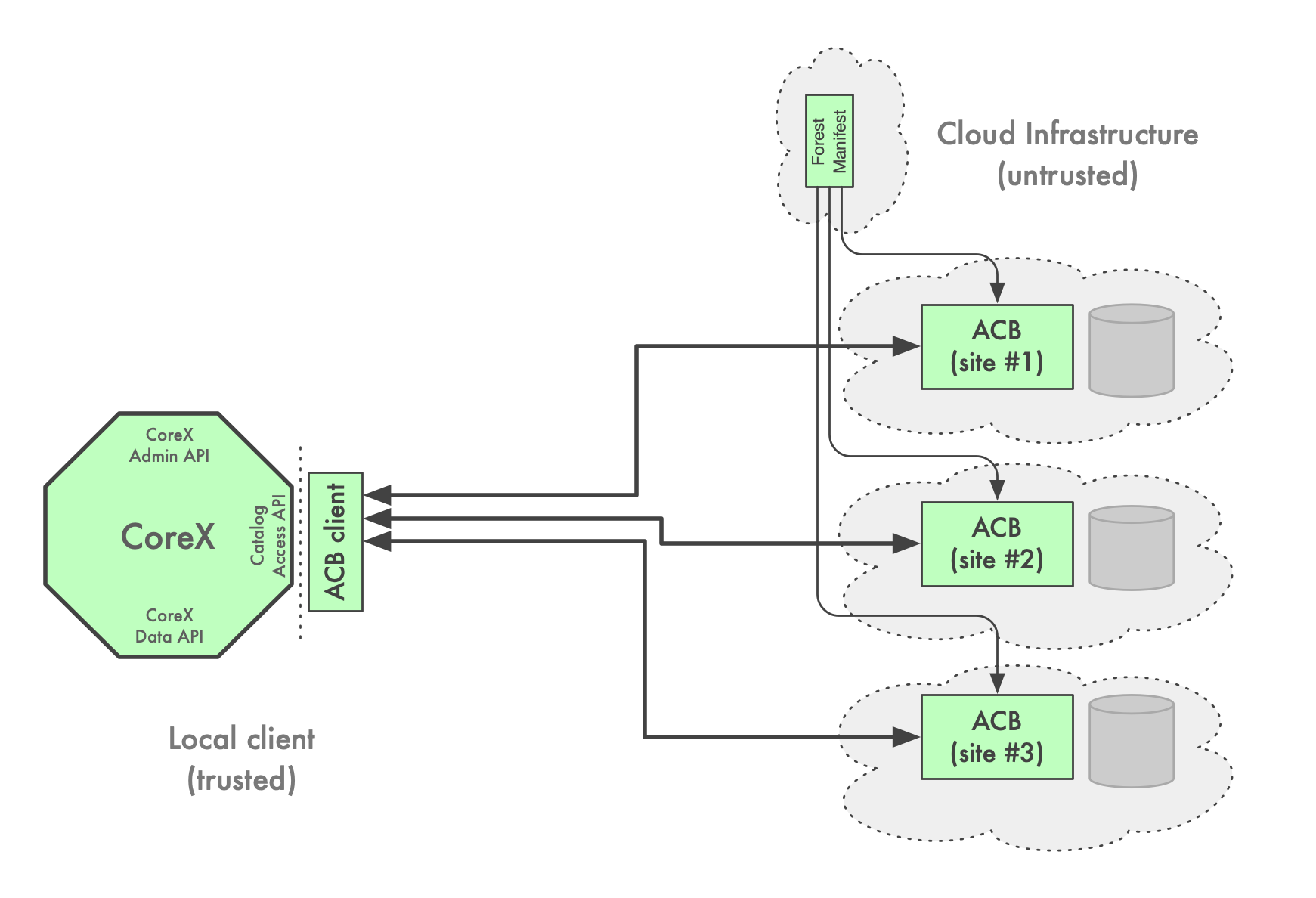
# Active Catalog Backend
Active Catalog Backend (ACB) is responsible for storing and (partly) managing the descriptors of all the containers belonging to a particular Forest (or more than one Forest). ACB typically runs in the cloud and sees (mostly) encrypted or somehow obfuscated data, such as encrypted container paths and encrypted storage descriptions (in particular storage access URLs and credentials). Generally, the ACB is expected to be untrusted, but specific (simplified or speed-optimized) implementations might not provide verification mechanisms, thus making this element trusted.
# ACB goals
In general, the ACB has two roles:
- Providing a (remote) storage for container descriptors, allowing access to this information from different machines,
- Improving performance of complex operations, such as querying or bulk editing of the metadata for many containers.
# Alternative ACB implementations
Wildland architecture does not specify the details of how an ACB should be implemented. Instead, only the local interface between the CoreX module and the ACB client is specified.
This allows for different implementations of ACBs, some optimized for speed, others for hardened security, some finding the balance between performance vs security and privacy requirements.
See Active Catalog Backend Implementation for more implementation-specific considerations.
# Redundant ACBs
A Forest manifest might specify more than one ACB endpoint, in which case it is assumed that all the ACBs represent the same data and any of them could be used for increased redundancy.
How the ACBs are kept in sync with each other is specific to a given ACB implementation. This means that the actual ACB syncing mechanisms are not part of the Wildland architecture. This is to allow the use of the native DB replication mechanism, which likely should provide performance benefits.
The side-effect of delegating replication mechanism to the ACB implementation is that ACBs of particular type (implementation) might only sync with other instances of ACB of the same kind.
# ACB integrity
While most of the data stored within the ACB is going to be encrypted, this does not automatically make the ACB a trusted element of a system (which would be very desirable, since we want to minimize the amount of trusted components, especially if they are executing outside of the user client system).
Indeed, a malicious ACB might, in the absence of any client-side integrity mechanisms, be shuffling the paths under which a given container is to be mounted within the user's system, or filter out some of the storages defined for a container.
Since different ACB implementations might implement integrity protection differently (e.g. one ACB might be using signed records in a relational database, while another might be utilizing Intel SGX enclaves), we delegate to the ACB client library to provide an integrity check of the returned data.
# Implementation Considerations
As mentioned above, the details of how ACB is to be implemented are intentionally left to the implementers to allow for usecase-specific optimizations. A reference implementation, provided by the Wildland Project, is discussed in the following document:
Active Catalog Backend Implementation considerations
# Differences with Legacy Wildland
- We got rid of the storage manifest objects and container manifest objects, replacing them instead with a defined API to the ACB, and allowing a different implementation to decide how to represent container descriptors. This is to allow for better performance and flexibility between performance and security.
- In legacy WL there was no notion of Active Catalog Backend, because static YAML files (container manifests) were used instead. This was to facilitate using static (dumb) storage for the whole infrastructure, as well as to enforce integrity protection on the architecture level (instead of on the ACB implementation level like in the new architecture) via manifests' signatures, but was occupied with very low performance on large forests.